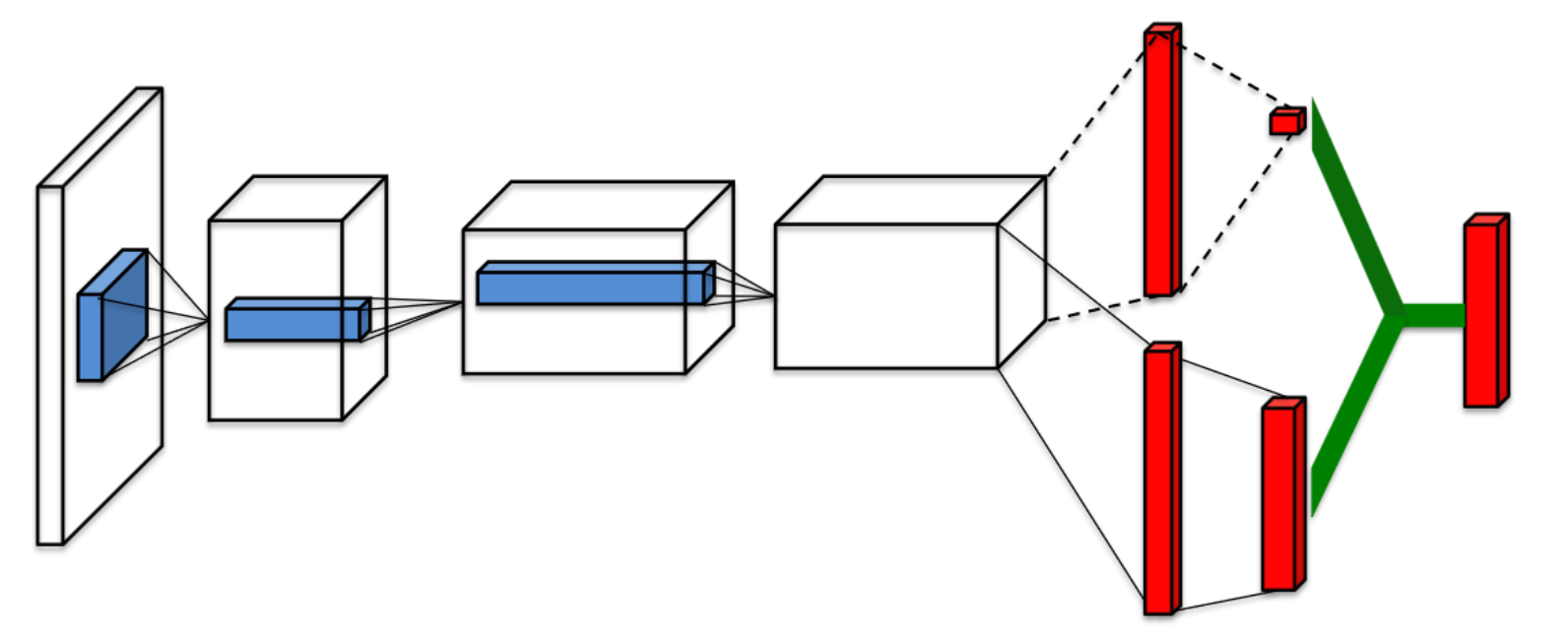

Introducing the “Dueling Network Architecture” in reinforcement learning, this paper breaks away from conventional neural network structures by independently estimating the state value function and state-dependent action advantage function. This novel factorization facilitates more effective policy evaluation in scenarios with multiple similar-valued actions, all while seamlessly integrating with existing reinforcement learning algorithms. The paper’s results demonstrate that this groundbreaking approach outperforms state-of-the-art methods in the challenging Atari 2600 domain, offering a promising leap forward in the realm of artificial intelligence and game-playing agents.
Link to the paper: https://arxiv.org/abs/1511.06581